CUDA Learn
01 向量加
nvcc compiler识别kernel call:
add<<<N, 1>>>(); // N block parallel, 1 thread each block
组织:
grid,block,thread:block代表一组worker,可以完成一块任务;__global__关键字,会向compiler提示这是一个kernel函数,需要在GPU上运行:__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x]
}block的下一级为thread,如下所示为thread parallel:
addVec<<<1, N>>>(); // 1 block, N thread parallel each block
__global__ void add(int *a, int *b, int *c) {
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x]
}支持任意长度:
__global__ void add(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x
// 一般来说,计算的数据长度不一定刚好就是blockDim.x(块的线程数量)的整数倍,
// 所以这里的index可能超时实际的长度,需要加上如下的if判断
if (index < n) { // thread check
c[index] = a[index] + b[index]
}
}此时在调用该kernel时,需要对分配的block向上取整数,以让其有足够多的block, thread来完成计算:
add<<<(N+M-1) / M, M>>>(d_a, d_b, d_c, N);
每个block中threads数量限制为:
[1-1024];
02 shared memory
- blocks -> threads
- 先将问题分解为block,在该层级提供了block内threads数据交互、同步等能力;
- shared memory是on-chip,通过
__shared__关键字识别,属于block级别,block间shared memory隔离; - 示例一维卷积操作:
场景: 以7个元素计算一个目标元素,这里定义radius=3
问题拆解:
- 每个output元素用一个线程来计算;
- block维度:
blockDim.x; - 每个output元素需要相邻的7个元素作为输入,这里涉及到数据共享以达到最优性能;
- 以单个block为第一层级视角,其中有
blockDim.x个线程,即有blockDim.x个output;
计算步骤:
- 以每个block为视角, 我们需要加载的SMEM大小即输出元素个数为:
smemLen=blockDim.x + 2*radius,因此需要将提供分配该大小的SMEM,并从global mem中加载进来,以让该block下的threads共享; - 每个thread完成自己的计算,共
blockDim.x个; - 将这
blockDim.x个output写回global memory;
如下所示,我们可以实现如下版本kernel:
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[blockDim.x + 2 * RADIUS]; // static allocation
int gindex = threadIdx.x + blockIdx.x * blockDim.x; // global index
int lindex = threadIdx.x + RADIUS; // local index in smem
// read smem from global memory
temp[lindex] = in[gindex];
// read left/right halo
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + blockDim.x] = in[gindex + blockDim.x];
}
// do caculation with stencil
int result = 0;
for (int offset = -RADIUS; offset <= RADIUS; offset++) {
result += temp[lindex + offset];
}
// write result to global memory
out[gindex] = result;
}但上述实现有一个bug: CUDA block内threads的执行是无序+并行的,因此上述代码中for循环执行时,并不能保证相邻的RADIUS的in元素已经加载到了SMEM,因此会存在bug;
解决的方式:引用block-level的
barrier:__syncthreads();来同步block内所有threads:...
// read smem from global memory
temp[lindex] = in[gindex];
// read left/right halo
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + blockDim.x] = in[gindex + blockDim.x];
}
__syncthreads();
// do caculation with stencil
int result = 0;
for (int offset = -RADIUS; offset <= RADIUS; offset++) {
result += temp[lindex + offset];
}
...SMEM属于block-level,其存在size limits:
48KB;这个
48KB数值,暂时不确定是固定的,还是随GPU架构的不同而不同,这应该与1个SM能不能同时并行调度多个block计算?:
L1 SMEM per SM: v100: 96KB, A100: 164KB, H100: 228KB早期的GPU架构没有SMEM,后面SMEM越做越大,不同的架构SMEM不同,所以同一套代码其性能可能会表现不同;
SMEM vs DRAM(global-memory): DRAM数据的读取,为了高效,其会以
segment来单位,如一次读取32B数据,无法做到只读32个数据中的一部分或单个B;而SMEM类似是一种static RAM 二维数组,其可以精确读取指定数量/位置的数据;dynamic SMEM size demo: 数组尺寸保留为空,尺寸通过调用时的第三个尖括号参数来定义:
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[]; // dynamic allocation
...
}
int smem_size = 192; // smem数据量大小
stencil_1d<<<grid_size, block_size, smem_size>>>>();在kernel中没有能直接获取到SM SMEM总尺寸的变量,但可以通过传参的方式提供进来;
03 GPU Architecture
GPU由SM组成,SM决定了GPU的架构:其定义了GPU的特性、能力、指令集;
GPU大小可以直接通过扩展SM来决定;
对同一代构架的GPU来说,cores (SP Unit - single precision float point)数量直接影响了SM的处理能力,但对于不同架构来说,不能直接以数量来比较性能;
SP unit可以执行: SP float add, SP float multiply, SP FMA;
DP unit: double precision;
LD/ST units: load/store units;
64K registers;
warp schedulers: SM指令分发单元;
Maxwell 5.2/Pascall 6.1: 引入了INT8 - 4个INT8算力等效于1个INT32算力(都在INT unit上计算);
VOLTA 7.0:
- 引入FP16(仍然还是在SP unit上计算) - 2个FP32算力等效于1个SP算力, 所以计算rate:2*SP;
- TensorCore:matrix * matrix in FP16;
GPU的架构发展,是有越来越多的SM,所以也意味着有更多的计算单元/并行能力,因此CUDA编程的一大挑战就是如何尽可能的利用起所有的threads,同时还能自动适应不同的GPU架构;
Tesla Datacenter级 vs Geforce Consumer级 GPU
- Tesla主动用于高性能通用计算,而Geforce用于消费端,对高精度、高性能计算要求不是那么高;
- Tesla用的是ECC内存,而Geforce不具备该能力;
- 另一个明显的区别会是在DP:SP的比例上,Tesla一般具备更高的比例,如DP:SP=1:2,而Geforce则一般具备更低的比例,如1:32,这是因为通用Graph计算用不着这么高的精度,所以只需要很少数量的DP unit即可;
warp and block
block被分到一个SM后,其在SM的调度与指令执行是以warp为单位,warp有固定的32个treads;
warp的概念就是真正代表了GPU的
SIMT的实现,即warp中的线程总是执行同一个指令;GPU指令执行是in-order,不像CPU被编译后可能会是out-of-order(乱序)执行;
GPU支持双发指令的能力,即可warp scheduler可以在一个时钟周期内发送两条指令的能力;
一个SM上能够允许调度的warp数量是有限的,一般为64或32,对应一个SM的线程数上限为:2048或1024;
所以block size需要设置为32(warp size)的整数倍,一条指令执行时对应着warp size数量的unit如SP在同时执行;
warp之间的调度/切换将由warp scheduler完成;
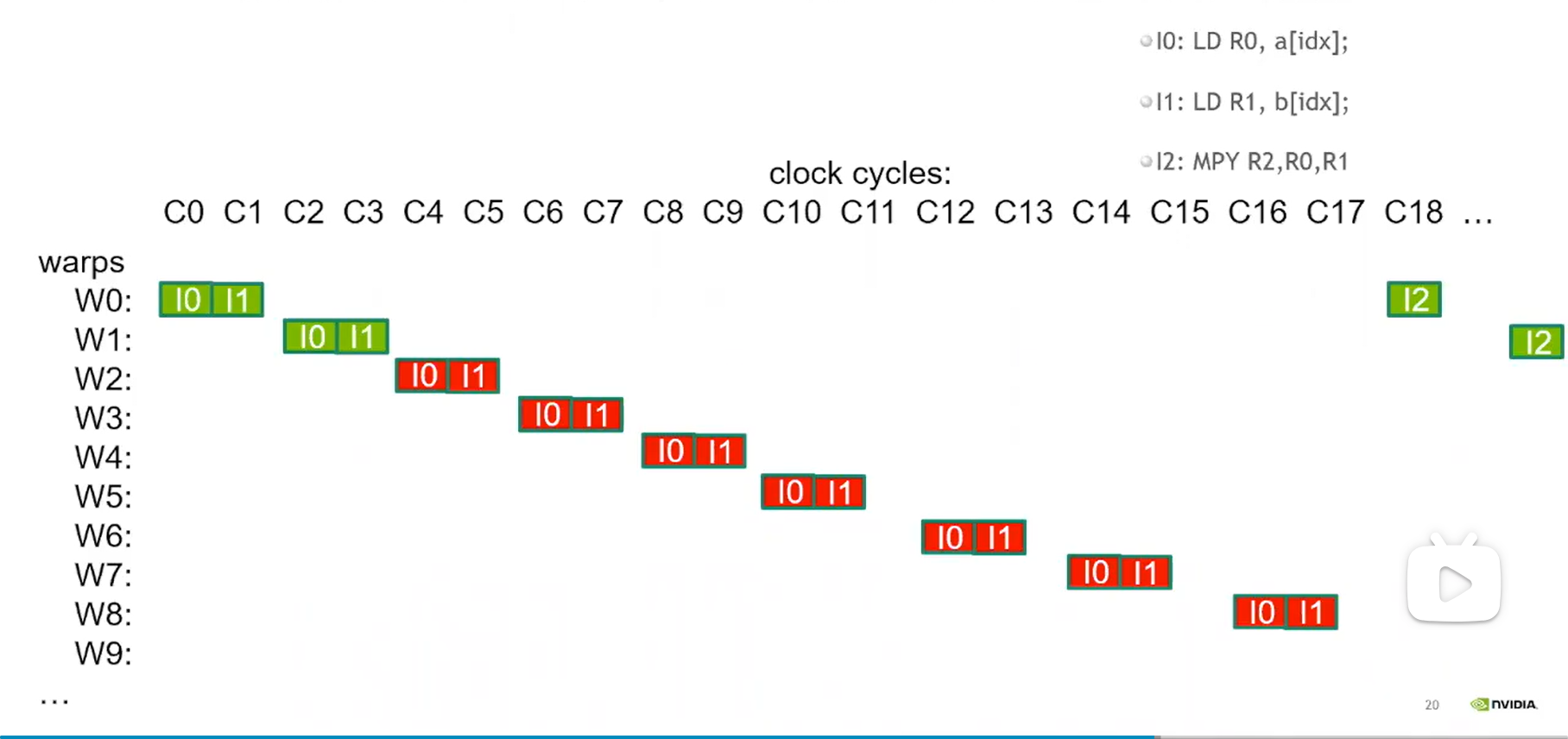
如上图所示,在CUDA开发中,我们应该利用大量线程来隐藏内存访问的开销,以达到最优性能;
同时在性能优化上,我们也应该尽可能最大化利用起内存带宽;
很显然,每个thread一次性读的数据越多,就可以有更少的线程打满内存带宽;
一个SM上可以同时调度多个block,但一个block只能固定调度到一个SM上,执行过程不会被重新调度到其它SM上;
block size选择
- 过大的blocksize,如直接取上限1024,则调度上不灵活,而过小的blocksize则性能不佳,因此一般会选择设置为如
128, 256, 512这些值;
SM OCCUPANCY
- 代表了一个SM的真实线程负载或利用率的指标;
- 可能受多个因素的限制:
- 每个线程的寄存器数(这个值可在编译时决定,是固定的);
- threas per threadlock;
- sharememory的使用情况;
share-memory
- 功能:提升性能、实现inter-thread数据通信;
- SMEM bank confilict ??
05 atomic, reductions, warp shuffle
managed/unified memory
一种GPU/CPU内存直接关联,并按需分布、数据自动同步的能力,通过类似page fault的技术实现:
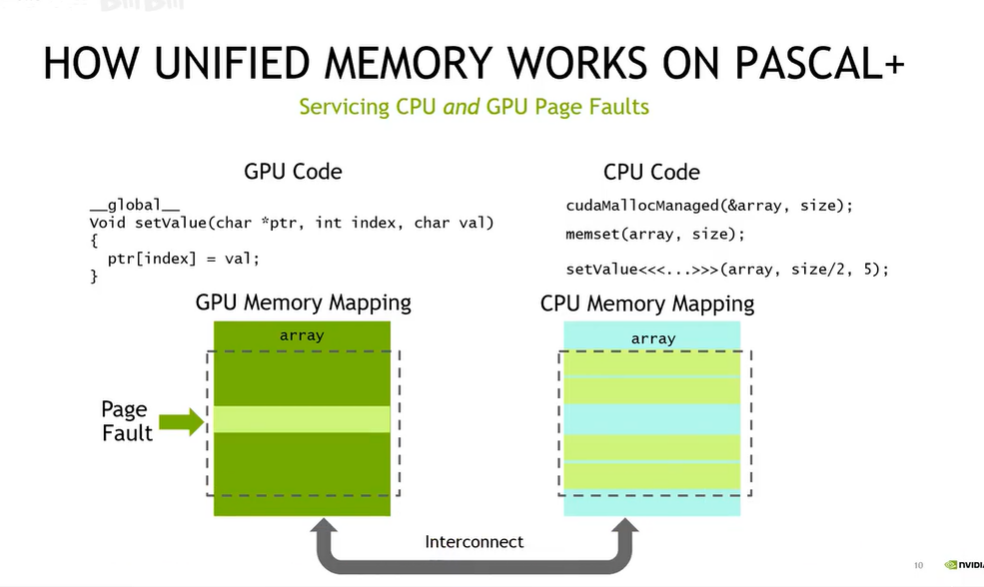
GPU memory oversubscription, pages are be migrated to GPU on demand:
void foo() {
// GPU has 16GB memory
char *data;
// size_t size = 64ULL*1024*1024*1024;
cudaMallocManaged(&data, size);
}支持系统级原子操作,支持CPU/GPU/多GPU;
统一内存并不是为了性能优化,主要是为了简化程序开发,甚至该技术的引入因大量的page-fault需要系统介入反而会引入性能下降;
explicit prefetching:
cudaMemPrefetchAsync(ptr, len, dstDevice, stream),可以将其类比于cudaMemcpy(Async),该能力的引入就可以批量移动数据,避免大量page-fault;UM相关资料:

streams
- 同一个stream上的指令的执行顺序一定是issue的顺序,不同stream上的指令的顺序不保证顺序性;
- Default stream with other streams: 当default stream与其它主动创建的streamm同时运行时,default stream的执行有一点特殊性,即在default stream执行前,会等待其它stream的任务全部完成后才开始,同时在default stream执行过程,其它stream将等待,直接default stream结束后才能开始;
- 为了避免出现上述的default stream的复杂性,一般如果使用多流,则建议全部使用name stream,在CUDA7后运行将默认stream设置为name stream的特性;
cudaLaunchHostFunc()运行在cuda stream中以stream的顺序来执行host函数(在该函数里,不能调用cuda API);- cuda api是线程安全的,可以在一个线程上执行
cudaAllocate,在另一个线程中执行cudaMemCpy;
stream priority
- CUDA streams运行定义优先级;
- CUDA block scheduler会尝试先调度具有更高优先级的stream的kernel blocks;
- 当前的实现不支持blocks的抢占调度;
cudaStreamCreateWithPriority()
multi-gpu
- 流是与device绑定的,如切换到其它device执行stream,会报错;
- 设备间支持显存直接传输,可以通过
cudaDeviceCanPeerAccess()来测试两卡之间是否可以通信(PCIE, NVlink);
cuda graph
- CUDA10中引入,由多个计算任务节点(node),如memcpy, kernel等组成;
- 一次定义,可以多次使用;
- 其优势是可以减少cuda kernel的启动开销;