k8s device-plugin
k8s device-plugin机制
docker运行GPU容器
- nvidia的GPU容器镜像原理是:NVIDIA驱动相对更稳定,因此容器中使用容器封装的CUDA/SDK库,共用宿主机的NVIDIA驱动;
- docker运行GPU容器时,需要将NVIDIA驱动映射到容器内:
# 以下的命令与nvidia-docker同样的作用原理
docker run --it --volume=navidia_driver_xxx.xx:/usr/local/nvidia:ro \
--device=/dev/nvidiactl \
--device=/dev/nvidia-uvm \
--device=/dev/nvidia-uvm-tools \
--device=/dev/nvidia0 \
nvidia/cuda nvidia-smi
k8s 运行GPU容器
- 安装NVIDIA驱动;
- 安装NVIDIA Dcoker:
nvidia-docker2 - 部署NVIDIA Device Plugin:
device-nvidia-plugin
k8s GPU资源插件原理
利用了两种技术:
- Extended Resources,允许用用户自定义资源扩展,如这里的扩展:
nvidia.com/gpu: 2, 也可用于如RDMA, AMD GPU, FPGA等; - Device Plugin Framework,允许第三方设备提供商以插件外置的方式对设置的调度和全生命周期管理;
Go Knowledge
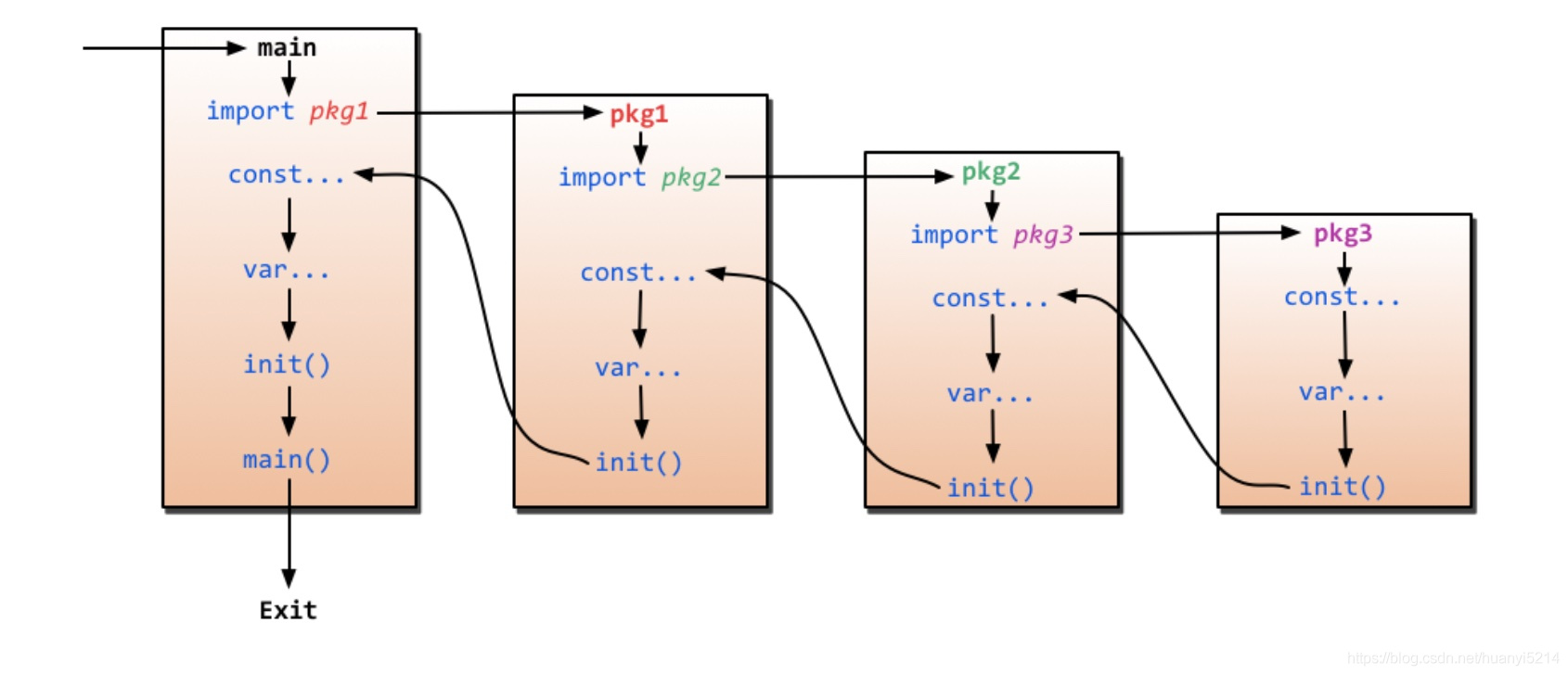
etcd
pod
pod内容器共享空间
资料
- https://www.cnblogs.com/rexcheny/p/11017146.html
- https://linchpiner.github.io/k8s-multi-container-pods.html
问题
k8s的pod内可以同时容纳多个容器,那这些容器之间有哪些资源(命名空间)是可以共享的?
答案
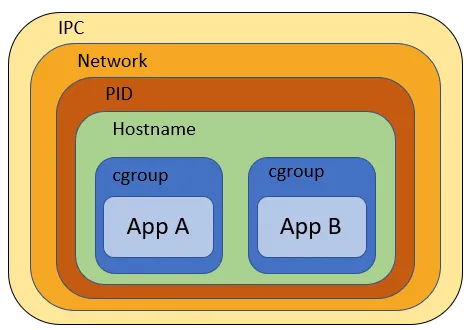
容器的隔离技术是通过cgroup和namespace隔离实现,linux支持namespace有:
- UTS名称空间,保存内核版本,主机名,域名
- NET空间,通过逻辑网络栈实现网络空间的隔离
- 进程PID空间,通过fork时指定的一个参数控制,不同空间间的PID是隔离了,看不到彼此的PID,子空间看不到父空间的内容,但父空间可以管理子空间,如发送信息
- IPC空间,即进程间通信的隔离,不同容器之间无法通过如信号量,队列,共享内存(System V IPC和POSIX消息队列),来实现进程间通信
- USER空间,实现用户,组相关功能的隔离
- MNT空间,即磁盘挂载点和文件系统的隔离能力,同一主机上的不同进程访问相同的路径能看到相同的内容,是因为他们共享本机的磁盘和文件系统
- 文件系统:不同容器都有自己的一个snapshotter目录,文件系统是隔离的
pod内的不同容器之间的共享稍有不同:
- UTS名称空间,是共享的
- USER空间,共享的
- NET空间,是共享的,因此不同容器启相同端口会冲突
- PID空间,默认是关闭的,可以通过
shareProcessNamespace: true打开 - IPC空间,是共享的
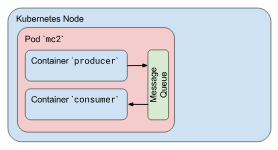
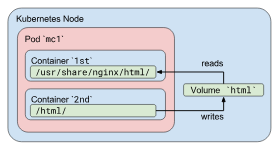
- MNT空间,隔离的,但可以通过挂载同一个pod volume来共享挂载的内容,实现不同容器间的共享挂载,但不同容器之间的文件系统是隔离的
k8s client-go
client
- k8s client-go提供4个client:
RESTClient,ClientSet,DynamicClient,DiscoveryClient
RESTClient
- 作为另外三类client的基类,提供与k8s apiserver的底层API请求构造与请求;
ClientSet
- 用于方便访问k8s内置api group资源的client,如deployment, pod等;
DynamicClient
- 通过指定资源组,资源版本即可操作k8s中的任务资源,包括CRD和内置资源;
- DynamicClient使用嵌套的
map[string]interface{}结构来存储k8s apiserver的返回资源结构,通过反射机制,在运行时进行数据绑定;
DiscoveryClient
- 与前面三种client不同,该client不是用于管理k8s资源对象的,该client是用于查询k8s支持的GVR资源类型的,与
kubectl api-versions和kubectl api-resources返回的资源内容相关;
raft
cni
容器网络
docker网络模式
- 默认创建如下三种:bridge, host, none
hbb@hbb:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
3c92bea4cc95 bridge bridge local
3d964312d0b5 host host local
07d5e640e74f none null local - 默认容器均采用bridge网桥模式,所有容器均会创建一对虚拟网络接口,容器内一个eth0,容器外一个vethXXX,vethXXX属于docker0,通过docker0实现对外网的访问;
host模式即与主机共享网络空间,不使用私有的容器网络空间;none模式即容器内没有eth0网口,因此无法与容器外通信;
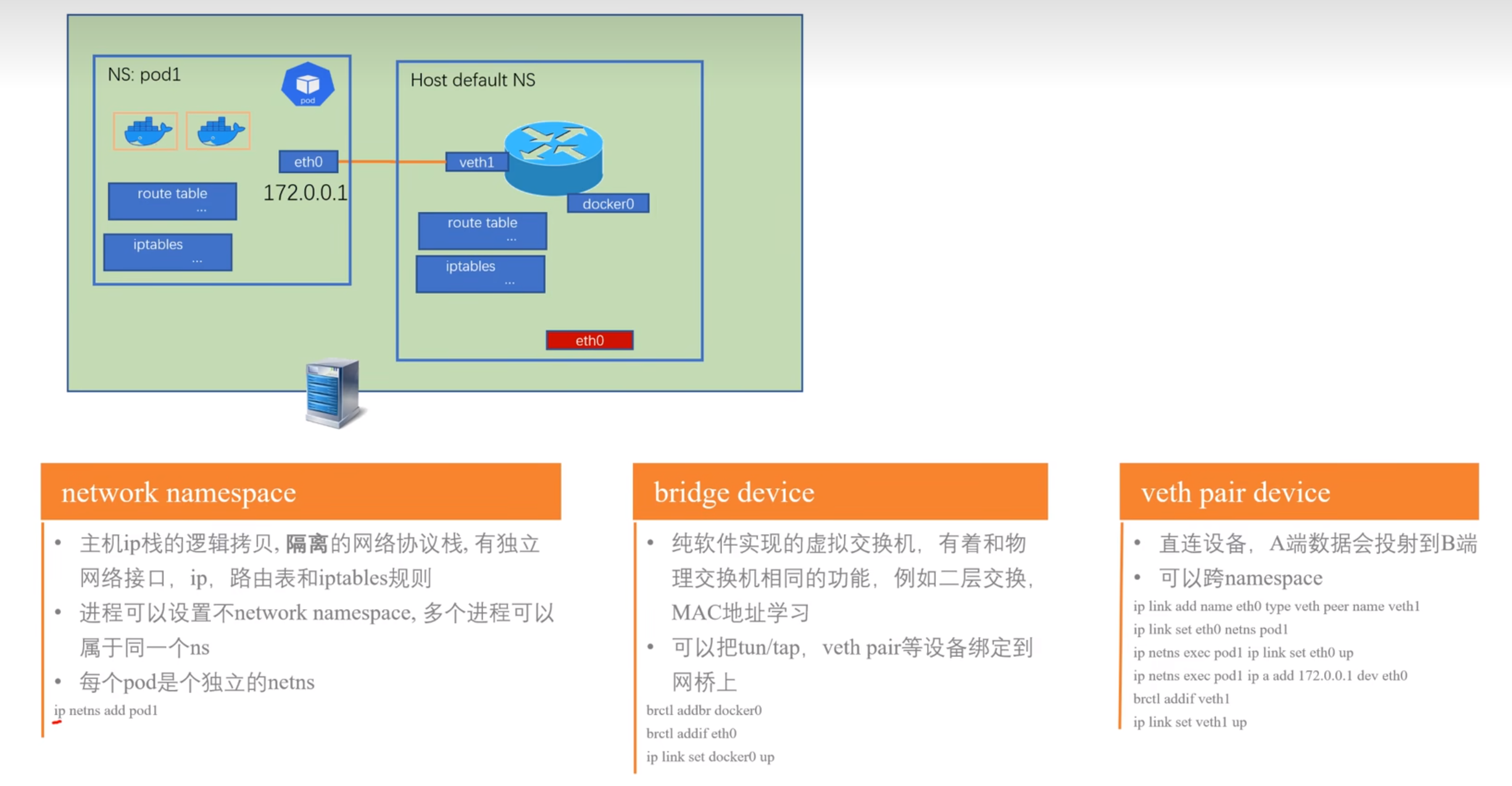
network namespace, veth pair, bridge
- 下图所示为相关概念:
bridge
- docker0 bridge即纯软件实现的虚拟交换机,可实现与物理交换机同样的功能,如二层交换,ARP寻找MAC地址;
network namespace
- 即将一个物理的网络协议栈进行逻辑隔离,形成网络空间,不同的拷贝协议栈有自己独立的网络接口,ip,route tables, iptables等,而进程可以设置使用不同的network namespace,多个进程也可以属于同一个ns,一个pod有一个独立的ns,pod内的容器属于同一个ns;
容器网络通信模型
- pod内容器属于同一个网络空间,所以可直接相互访问;
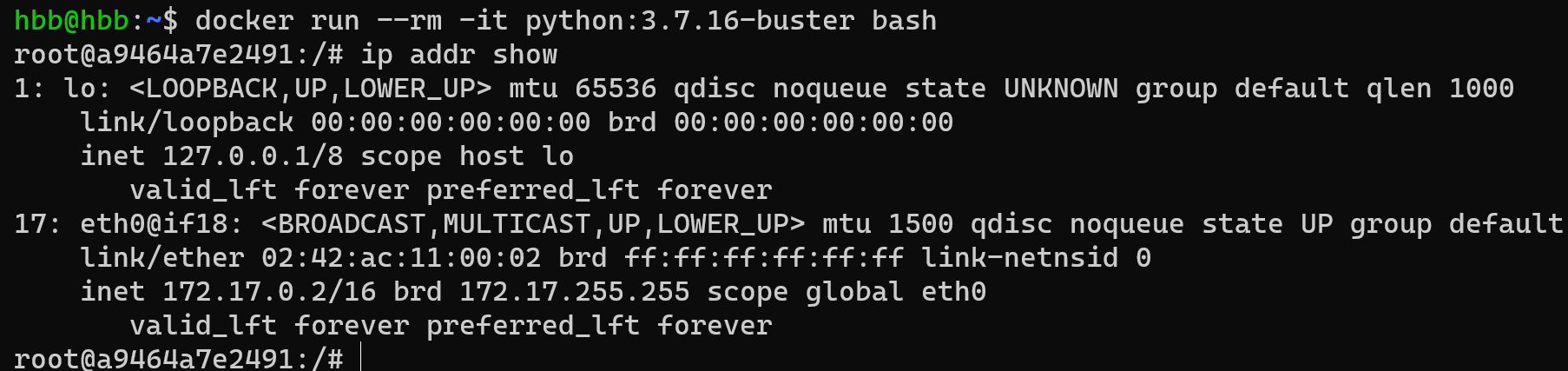
- 同机不同容器之间,通过虚拟以太网veth network互联,docker安装后,会默认创建一个docker0作为虚拟以太网的bridge网桥,在容器创建时会在容器内外创建一对虚拟网络接口,容器内为eth0,容器外即主机上会对应创建一个vethXXX名的接口名,如下图所示:
- 该图为docker容器内eth0,与docker0属于同一网段:
- 该图为上面容器在主机上对应的veth网口,其master为docker0:

- 该图为docker容器内eth0,与docker0属于同一网段:
- 在主机上通过
docker inspect network bridge命令可查看docker列出的当前docker默认bridge网桥docker0下的容器网络信息: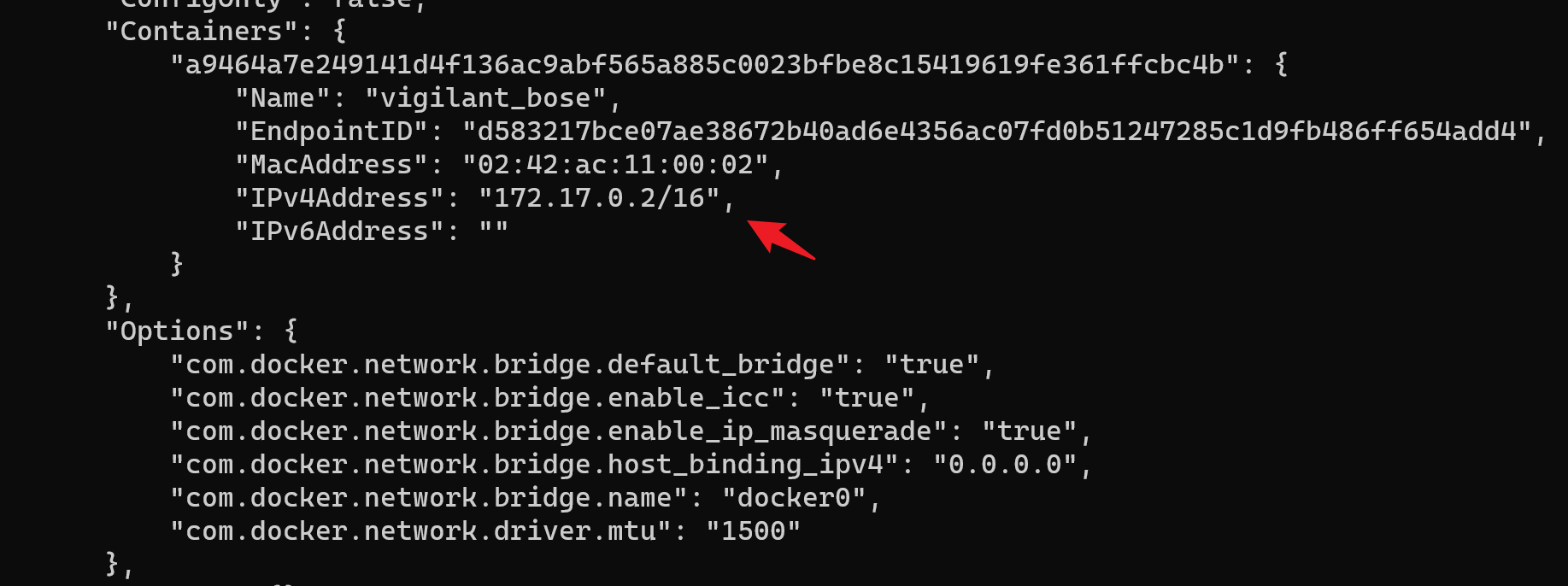
Go Channel
原理
- 本质上,channel是一个包含:发送Go队列,接收Go队列,由循环数组实现的缓存数据队列,锁这几个元素组成的结构体实现;
sendmsg阶段:- 如果接收Go队列有值,则直接进行值元素的内存拷贝,并唤醒接收队列;
- 如有缓冲队列且未满,则将值复制到循环队列中;
- 如果有缓冲队列且满了或无缓冲队列,将协程放到channel的
sendqueue中;
recvmsg阶段:- 如果缓冲,且无数据,则进入
recvqueue中,协程挂起(gopack); - 如果缓冲队列中数据,由从队列中将值拷贝给当前接收者;
- 如果
sendqueue有协程,则说明缓冲队列已满,则从缓冲队列中取值,并将sendqueue中取一个协程,将其值拷贝到缓冲循环数组中;
- 如果缓冲,且无数据,则进入
- 上述操作是在mutex锁下进行,所以channel是协程安全的;
Go GMP and Scheduler
资料
- https://medium.com/@sanilkhurana7/understanding-the-go-scheduler-and-looking-at 1-how-it-works-e431a6daacf
- https://segmentfault.com/a/1190000041860912/en
结构
原理
- G:协程,P:processor,M:系统线程,M绑定一个P才能执行G;
- P的数据是控制着Go的并发能力,由环境变量
GOMAXPROCESS控制数量,线程数一般不配置,但也有一个底层的函数可设置(SetMaxThreads),M默认上限是10000; - P的存在是为了实现G的调度和M/G之间M:N的关系;
- P有一个local queue,无锁,当P的local queue无G时,会从Global queue取,此时需要用锁,而如果Global queue也无G时,会走work stealing,尝试从其它P的local queue上找G运行;
- G的抢占调度是基于时间片,即如果G长时间连续运行超过10ms,则会通过系统信号SIGURG强制调度该协程;
- 当G发生阻塞,如系统调用IO操作时,会创建一个新的线程或利用一个空闲的线程来绑定当前P,以继续执行P上的G,而旧线程进入阻塞睡眠状态;
- P的local queue放的G的数量上限为256;
- 当因IO阻塞进入idle状态的线程,在G系统调用结束时,因此时M上没有P了,而G的执行一定需要P,所以会尝试先去获取一个idle的P来执行,如找到了,则会将该G放到该P的local queue中,如果没有,则M会进入idle线程队列,G会放到Global queue中;
Go GC
Go1.5 标记删除(Mark and Sweep)
原理
- 进入STW(Stop The World)阶段
- 遍历整个heap,排查未被引用的对象,并标记;
- 暂停STW
- 执行Sweep清除
缺点
- STW会让Go程序暂停,程序出现卡顿
- 标记需要扫描整个heap
- 清除数据会产生heap碎片
Go1.8 三色标记法 + 写入屏障
三色标记法
原理
- 维护三个标记表:
白色,灰色,黑色 - 程序初始时,所有对象标记为白色
- 从Root Set开发,每次只遍历一层,标记该层的对象为
灰色(对象从白色表中移到灰色表) - 然后,以
灰色标记表开始,遍历该表中的对象,将从这些对象开始的可达到对象(走一步),标记为灰色,同时灰色表中已经遍历过的对象,标记为黑色(对象从灰色表中移到黑色表) - 循环上一步,继续遍历
灰色表,直到灰色表中无任何对象 - 剩下的白色即为需要删除的对象
上述过程,仍然需要STW,否则会出现并发导致的引用关系错乱,导致资源被错误的GC删除
kubeadm初始化k8s
init
节点环境准备
- 关闭swap
# 查看
sudo swapon --show
# 关闭
sudo swapoff -a - 配置其它:
# sudo vim /etc/sysctl.d/k8s.conf
# 添加:
net.ipv4.ip_forward = 1
# 导出配置
containerd config default > /etc/containerd/config.toml
# 修改配置
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
# 执行命令
sudo modprobe br_netfilter
sudo systemctl restart containerd - 按正常流程安装完docker, containerd组件
Karmada
资料
背景
- karmada是由华为开源的云原生多集群容器编排平台,在kubernetes Federation v1, v2(
kubefed)的基础上发展而来,吸取了其经验和教训,kubefed项目目前已经被放弃; - 其特点是在保存原有k8s资源定义API不变的情况下,通过添加与多云应用资源编排相关的一套新的API和控制面板组件,为用户提供多云/多集群容器部署,实现扩展、高可用等目标;
- 如下图所示为
kubefedv2接入vs时需要定义的CRD,因此接入kubefed是需要对原始k8s资源进行改造,对用户不友好:apiVersion: types.kubefed.io/v1beta1
kind: FederatedVirtualService
metadata:
name: service-route
namespace: default
spec:
placement:
clusters:
- name: cluster1
- name: cluster2
- name: cluster3
template:
metadata:
name: service-route
spec:
gateways:
- service-gateway
hosts:
- '*'
http:
- match:
- uri:
prefix: /
route:
- destination:
host: service-a-1
port:
number: 3000
containerd
资料
https://github.com/containerd/containerd/blob/main/docs/historical/design/architecture.md
https://blog.frognew.com/2021/05/relearning-container-08.html
https://blog.frognew.com/2021/06/relearning-container-09.html
https://blog.mobyproject.org/where-are-containerds-graph-drivers-145fc9b7255
高层架构
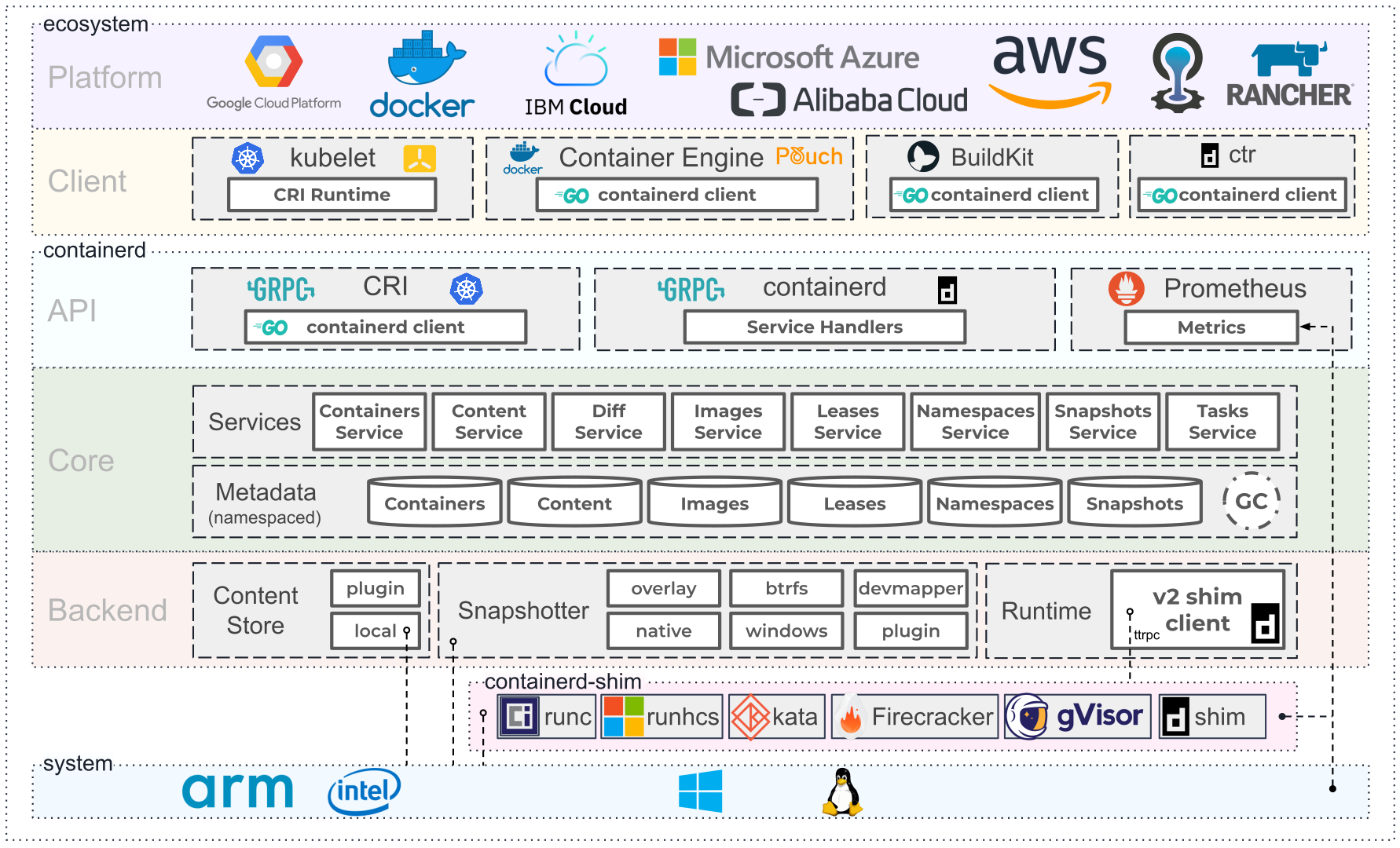
概念
联合挂载
- 由overlay filesystem提供的能力,支持将多个文件系统层叠加在一起,且只显示最顶层的文件和目录,OverlayFS是其实现,docker当前默认存储驱动为overlay2,就是基于该文件系统;
- 在contaierd中这个联合挂载的roofs视图是由snapshotter准备的snapshots;
Lazy Docker Containers
论文粗读:Slacker: Fast Distribution with Lazy Docker Containers
阅读目标
- 了解docker容器启动过程的数据特性,以及slacker的设计思路,不对该存储驱动做过细了解。
介绍
- 开发了名为
HelloBench的工具来分析57个不同的容器应用,分析容器启动过程的IO数据特性和镜像可压缩性,得出结论:在容器的启动过程中,镜像的拉取占76%的时间,但仅读了6.4%的数据。 - 基于这些发现,作者设计开发了一种新的docker存储驱动:Slacker,可以用于加速容器的启动速度。
- Slacker采用中心化存储思路,所有的docker workers和registries都共享这些数据。
- Container的启动主要慢在文件系统的瓶颈,相对而言,network, compute, memory资源更快且简单,容器应用需要一个完整的初始化文件系统,包括应用binary,完整的linux系统和依赖包;
- 在谷歌的研究论文中,容器应用启动延时变化秀大,中间值一般为25s,且package installation占了80%,其中的一个瓶颈为并发写磁盘的过程;
- 提供快启动的好处:
- 应用能快速扩容以应对突发事件(flash-crowd events);
- 集群调度器能以最少的代价频繁执行rebalance nodes;
- 应用更新或bug修复能快速发布;
- 开发者可以交互式构建和测试分发应用;